Tuning Engines
Tuning Engines is the elite unified runtime that securely governs, optimizes, and orchestrates every AI interaction through a single API with zero.
Visit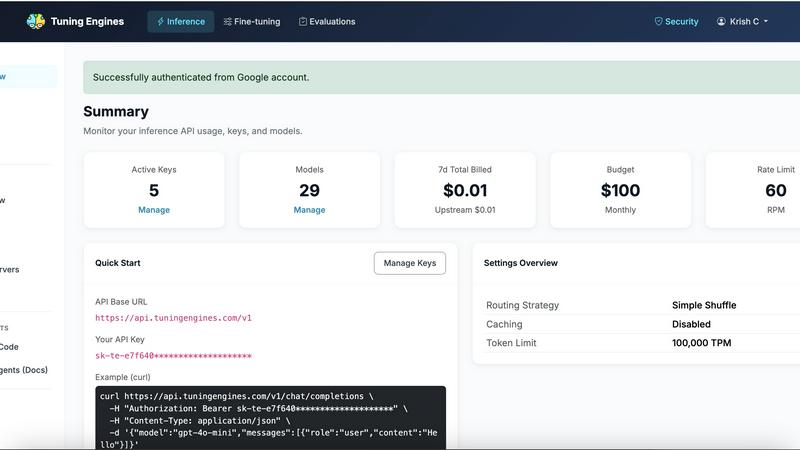
About Tuning Engines
Tuning Engines, by CerebrixOS, is a unified AI control and governance layer designed for elite engineering teams building production intelligence across models, agents, tools, and fine-tuned systems. It serves as a universal intelligence runtime that enables organizations to secure, govern, and optimize every AI interaction through a single, cohesive platform. This product brings together the full AI lifecycle in one governed environment, encompassing inference, model routing, fallback policies, fine-tuning jobs, datasets, evaluations, model imports and exports, custom models, agents, MCP servers, reusable skills, guardrails, policy-as-code, data capture, runtime traces, usage analytics, API keys, billing, team roles, and integrations. Developers gain access to OpenAI-compatible APIs, Anthropic-compatible routes, CLI workflows, MCP access, coding-agent integrations, and resource catalogs for models, agents, tools, and skills. Teams can seamlessly connect Claude Code, OpenCode, Aider, Cline, Roo, Continue.dev, Cursor, VS Code, Windsurf, and other AI workflows through this single governed platform. Administrators receive the controls essential for production environments, including role-based access, per-key budgets, rate limits, routing profiles, fallback rules, guardrails, policy-as-code, credential sources, auditability, usage traces, billing controls, tenant isolation, and team management. Tuning Engines is architected to help organizations transcend isolated AI experiments, establishing a secure, observable, cost-aware, and extensible AI operating layer where models can be trained, evaluated, routed, governed, and utilized by agents and tools at scale. A distinctive value proposition is that infrastructure costs are passed through at-cost with zero markup, meaning clients only pay for support and platform upkeep.
Features of Tuning Engines
Unified Inference
Access any model through one OpenAI-compatible endpoint, eliminating the complexity of managing multiple providers. This feature supports open models, commercial frontier models, and your own custom-tuned variants, all behind a single API. Developers can keep their existing SDKs, swap one base URL, and call any model with centralized policy, full auditability, and token controls applied to every request. Streaming and structured output are natively supported, ensuring seamless integration into existing workflows.
Model Tuning and Lifecycle Management
Adapt open models to your proprietary data, specific language requirements, and production goals through supervised fine-tuning and LoRA adapters. The platform manages the entire model lifecycle, from building with zero GPU setup to tuning with evaluation gates that ensure quality improvements align with business objectives. Organizations can host their own models without managing GPU infrastructure, reducing operational overhead while maintaining control over model performance and behavior.
Policy-as-Code and Governance
Implement centralized guardrails, access controls, and full request traceability across every model interaction. Administrators can define AGT YAML policies, set per-key budgets, enforce rate limits, configure routing profiles, establish fallback rules, and manage credential sources. This feature provides comprehensive auditability through runtime traces and usage analytics, ensuring every AI interaction is observable, secure, and compliant with organizational standards.
Token Economics and Cost Management
Maintain predictable spending with cost ceilings, quotas, intelligent routing, and fallback mechanisms. The platform provides detailed usage analytics, billing controls, and tenant isolation, enabling organizations to manage token economics at scale. Infrastructure costs are passed through at-cost with zero markup, ensuring transparency and eliminating hidden fees. Teams can monitor spend, optimize model selection, and enforce budgets across departments and projects.
Use Cases of Tuning Engines
Code Assistance and IDE Copilots
Engineering teams can build and deploy AI-powered code assistants that integrate directly into popular development environments like VS Code, Cursor, and Windsurf. The platform supports code generation, refactoring, debugging, and context-aware suggestions through a governed interface. Developers can leverage multiple models, apply fallback policies, and maintain full auditability of all code-related AI interactions, ensuring security and compliance in software development workflows.
Conversational AI and Customer Support
Organizations can deploy sophisticated customer support bots, internal helpdesks, and multilingual chat systems using the unified inference layer. The platform enables intelligent model routing based on query complexity, cost optimization, and fallback strategies to maintain uptime. Administrators can enforce guardrails, monitor sentiment, and analyze conversation traces to continuously improve response quality while controlling operational costs.
Agentic Systems and Multi-Step Reasoning
Build and deploy autonomous agents capable of multi-step reasoning, planning, and tool execution. Tuning Engines provides the infrastructure for agentic workflows, including MCP server integration, reusable skills, and tool catalogs. Teams can govern agent behavior through policy-as-code, enforce safety constraints, and audit every action taken by AI agents in production environments, enabling reliable and secure autonomous operations.
Enterprise RAG and Knowledge Retrieval
Implement secure, scalable retrieval-augmented generation over private knowledge bases and enterprise documents. The platform supports semantic search, personalized recommendations, and enterprise assistants that access proprietary data with granular access controls. Organizations can fine-tune models on domain-specific content, apply guardrails to prevent data leakage, and maintain complete audit trails of all retrieval and generation activities.
Frequently Asked Questions
How does Tuning Engines handle model routing and fallback policies?
Tuning Engines provides sophisticated routing profiles that allow teams to define intelligent model selection based on factors like cost, latency, quality requirements, and availability. Fallback policies ensure uninterrupted service by automatically redirecting requests to alternative models if the primary model fails or exceeds rate limits. These policies are defined as code using AGT YAML, enabling version control, testing, and consistent enforcement across all environments.
What is the pricing model and how does it differ from other providers?
Tuning Engines operates on a transparent pricing model where infrastructure costs are passed through at-cost with zero markup. Clients only pay for platform support and upkeep, eliminating the hidden margins common with other AI infrastructure providers. This approach allows organizations to scale AI operations without unpredictable cost inflation, making it particularly attractive for high-volume production deployments.
Can I use my existing OpenAI SDK and codebase with Tuning Engines?
Yes, Tuning Engines provides a fully OpenAI-compatible API endpoint. Developers can keep their existing SDKs and simply swap the base URL to https://api.tuningengines.com/v1/ to access over 100 models, including open models, commercial frontier models, and custom-tuned variants. No code rewrites or new client libraries are required, enabling seamless migration with minimal engineering effort.
What security and governance controls are available for production deployments?
Administrators have access to comprehensive security controls including role-based access management, per-key budgets and rate limits, credential source management, tenant isolation, and full request traceability through runtime traces. The platform supports policy-as-code with AGT YAML, enabling automated enforcement of guardrails, safety constraints, and compliance requirements. All interactions are auditable, providing complete visibility into model usage, costs, and behavior across the organization.
Similar to Tuning Engines
Distro
Instead of only telling you what to do, Distro helps execute the work: content, conversations, and outreach, done with approval workflows, safety cont
Skygen AI
Skygen AI empowers businesses to effortlessly automate workflows and create intelligent agents for enhanced productivity and efficiency.
HyperLake
HyperLake is a sovereign AI infrastructure that empowers autonomous agents with seamless, cost-effective, and governed data access in your cloud.
Adkumo
Adkumo transforms your URL into a complete brand-aligned ad campaign, shipping dozens of on-target variations to Meta and LinkedIn in minutes.
Minded
Record once to train elite AI agents that clear real tasks from your systems, managed in plain English.

YCaaS
YCaaS deploys autonomous AI agents to seamlessly execute every role across your entire workflow end to end.
xyOps
xyOps delivers elite infrastructure orchestration with intelligent automation, real-time monitoring, and advanced job scheduling for top-tier.

Playwriter
Playwriter lets AI agents control your actual Chrome browser with all your logins and extensions intact.