CloudBurn vs OpenMark AI
Side-by-side comparison to help you choose the right tool.
CloudBurn
CloudBurn prevents costly AWS surprises by showing infrastructure cost estimates directly in pull requests.
Last updated: February 28, 2026
OpenMark AI benchmarks 100+ LLMs on your task: cost, speed, quality & stability. Browser-based; no provider API keys for hosted runs.
Visual Comparison
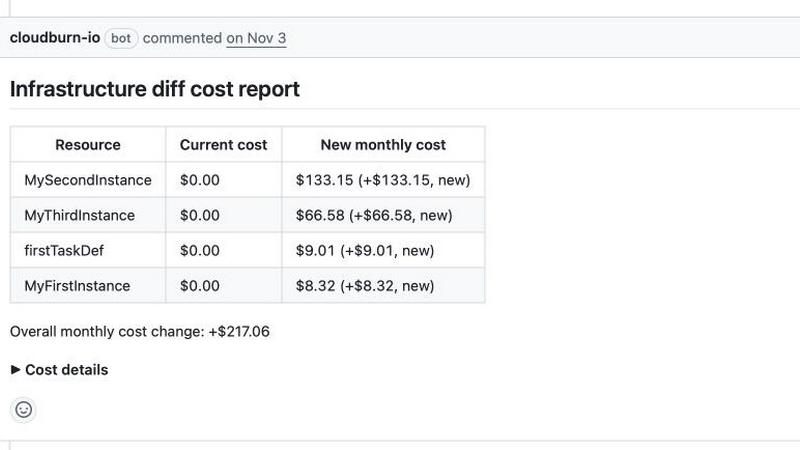
CloudBurn
OpenMark AI

Overview
About CloudBurn
CloudBurn is the definitive pre-deployment cost intelligence platform engineered for elite engineering teams operating in the cloud. It is purpose-built for organizations that leverage Infrastructure-as-Code frameworks like Terraform and AWS CDK, transforming the traditionally reactive and opaque process of cloud cost management into a proactive, transparent discipline. The platform's core mission is singular and powerful: to prevent expensive infrastructure mistakes before they are ever deployed to production. Traditional teams operate blind, discovering cost overruns weeks later on a static AWS bill, long after resources are provisioned and capital is irrevocably spent. CloudBurn disrupts this costly cycle by injecting real-time, granular cost analysis directly into the developer workflow—specifically, within the code review of a GitHub pull request. This creates an immediate financial feedback loop, empowering developers, architects, and FinOps practitioners to make informed, cost-conscious decisions when changes are simplest and cheapest to implement. By shifting cost governance left in the CI/CD pipeline, CloudBurn ensures financial accountability is baked into the development lifecycle from the first line of code, safeguarding budgets and enabling a true, automated culture of FinOps.
About OpenMark AI
OpenMark AI is a web application for task-level LLM benchmarking. You describe what you want to test in plain language, run the same prompts against many models in one session, and compare cost per request, latency, scored quality, and stability across repeat runs, so you see variance, not a single lucky output.
The product is built for developers and product teams who need to choose or validate a model before shipping an AI feature. Hosted benchmarking uses credits, so you do not need to configure separate OpenAI, Anthropic, or Google API keys for every comparison.
You get side-by-side results with real API calls to models, not cached marketing numbers. Use it when you care about cost efficiency (quality relative to what you pay), not just the cheapest token price on a datasheet.
OpenMark AI supports a large catalog of models and focuses on pre-deployment decisions: which model fits this workflow, at what cost, and whether outputs are consistent when you run the same task again. Free and paid plans are available; details are shown in the in-app billing section.